
阅读背景:
在阅读MongoDB 架构设计Replica Sets之前,请先阅读Kafka-架构设计的博文。用以对比。
1 : MongDB的架构设计之中,MongoDB支持多个机器之间通过异步复制达到故障转移和实现冗余,多台的机器之中只有一台是用于写操作,正是由于这个原因,在MongoDB之中只有一台充当了Primary角色的机器能把读操作分发给Slave。
MongoDB 高可用可以分为两种的方式:
1:master——Slave 主从复制,目前已经不怎么实用了
2:Replica Sets复制集
MongoDB 在1.6版之后加入了新的一个功能点叫做复制及:replica Set,增加了故障的自动切换和自动修复成员节点。各个DB之间的数据完全一致。大大降低了维护成功,
如图:
数学上来将,就是一个同构型的集合:也就是一个集群。MongoDB的Relica Set架构是通过一个日志来存储写操作的。这个操作就叫做”oplog“,oplog.rs 是一个固定长度的CappedCollection。这个Collection的位置存在于“Local数据库之中”,用于记录Replica Set操作的日志,它在默认的情况之下,对于64位的MongoDB,opLog是比较大的。可以达到5%的磁盘空间,oplog的大小是可以通过Mongod的参数 ”—oplogSize“来改变。
除了固定的复制集意外,还保持了较好的伸缩性,一旦需求得不到满足,那么就需要添加新的机器。那么句需要增加一些节点将压力平均分配一下。
增加节点的方式,一般可以通过oplog直接进行增加节点,操作简单并且无需人工干预,可是oplog是
capped collection,采用的循环方式进行日志处理,所以采用的是oplog的方式来添加,可能会有不一致的问题。
因为日志中间存储的信息由可能已经刷新过了。不过没关系。通常而言,你可以通过数据库的快照 --fastsync和oplog结合的
方式来增加节点。这种方式的操作流程是,先取某一个复制集成员的物理文件来作为一个初始化的数据,然后剩余的部分用
oplog的方式去添加。
而 Sharding,这是一种将海量的数据水平扩展的数据库集群系统,数据库分表存储在 sharding的各个节点之上。MongoDB的数据分块成为chunk,每一个Chunk都是Collection中一段连续的数据记录,通常的最大的尺寸是200MB。超出那么就会生成一个最新的数据块。这个和Hbase Region的分裂是一样的。
整个分拆的过程大致如下:

对于MongoDB
首先在CL: Client 这一层面来说,底层是否需要分片?是否需要这样的一个复制集对与使用者来说完全不必要知道。Mongos: 好比就是一个大管家,要怎么去分拆Collections?,你Client完全不必要知道,只需要你告诉我一个东西:分区的Key是什么?在很多的组件之中,包括在hadoop,Storm,等个各种数据库之中都会有这样的一个 Partition Key的概念。对应于我们的网络之上就会充当了这样一个路由的功能。并且将自己所把控的一些集群的信息存放在Config服务器之中。
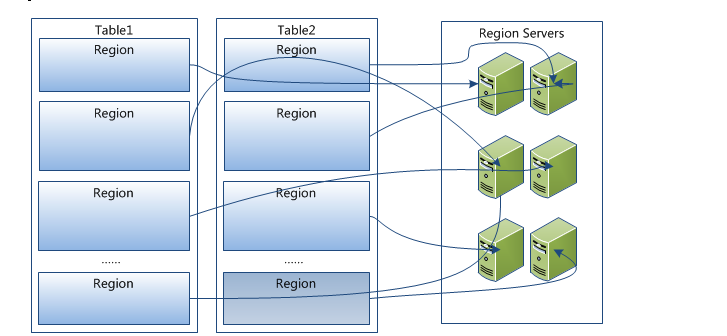
在其他的数据库中间也就是如此,对于Hbase。依然需要对于表再进行分拆。对应于Hbase之中的Region。和MongoDB的分片其实用一个比较常用的英文名字就叫做 Segment。
如果你对于Hbase之流不够了解没关系。你只是需要知道,Region是表分裂的一个片段,region按大小分割的,每个表一开始就只是一个Region,Region随着数据的写入会不断的扩大,以至于达到了设计阈值以后,Region就开始分裂了,由1分二。当table中的行越来越多的时候,Region的数量就越来越多。

HRegion是Hbase之中分布式存储和负载的最小的单位,在这里给出一个比照的图:如下:
而在kafka之中之中的Replication,其实更加相当于Hadoop体系之中的 【副本机制】,和分片所需要解决的矛盾不同。

简单的额来说,分布式系统有自己独特的属性与性质,对于其存存储体系有着固定的诉求。
如果您对于大数据体系整个副本的存储,策略保持好奇,请参考本ID的另外一篇博文:
c。